






生物技术通报 ›› 2024, Vol. 40 ›› Issue (10): 76-85.doi: 10.13560/j.cnki.biotech.bull.1985.2024-0523
纪宏超1( ), 李正艳1,2,3
), 李正艳1,2,3
收稿日期:2024-05-31
出版日期:2024-10-26
发布日期:2024-11-20
通讯作者:
纪宏超作者简介:纪宏超,男,博士,研究员,研究方向:生物信息学;E-mail: jihongchao@caas.cn
基金资助:
JI Hong-chao1(), LI Zheng-yan1,2,3
Received:2024-05-31
Published:2024-10-26
Online:2024-11-20
摘要:
次生代谢产物研究对于植物生长发育、环境适应以及人类健康和药物研发具有重要意义。液相色谱-质谱联用平台(LC-MS)已成为次生代谢研究的首选策略。然而,代谢物结构解析仍受限于标准谱图库覆盖度不足的问题。由于代谢物结构数据库的覆盖度远高于标准谱图库的覆盖度,通过人工智能方法建立代谢物结构与谱图之间的关联,从而实现基于质谱谱图搜索结构数据库是解决这一问题的有效途径。论文综述了通过深度学习技术和生物信息学方法建立代谢物结构与谱图之间联系的三种策略,包括通过结构预测谱图、通过谱图预测结构和通过已知推测未知,并介绍了每种策略解决问题的思路和代表方法。对于每种策略,论文讨论了其算法的优势和不足,以及在实际应用中可能遇到的挑战。此外,还探讨了在开发新算法和进行基准测试时应注意的因素,以及这些因素如何影响对算法的评估。最后,指出了融合更多正交信息是实现更加准确的代谢物注释的未来方向。
纪宏超, 李正艳. 基于质谱的未知次生代谢物结构解析研究进展与展望[J]. 生物技术通报, 2024, 40(10): 76-85.
JI Hong-chao, LI Zheng-yan. Research Progress and Prospects in the Structural Annotation of Unknown Secondary Metabolites Based on Mass Spectrometry[J]. Biotechnology Bulletin, 2024, 40(10): 76-85.
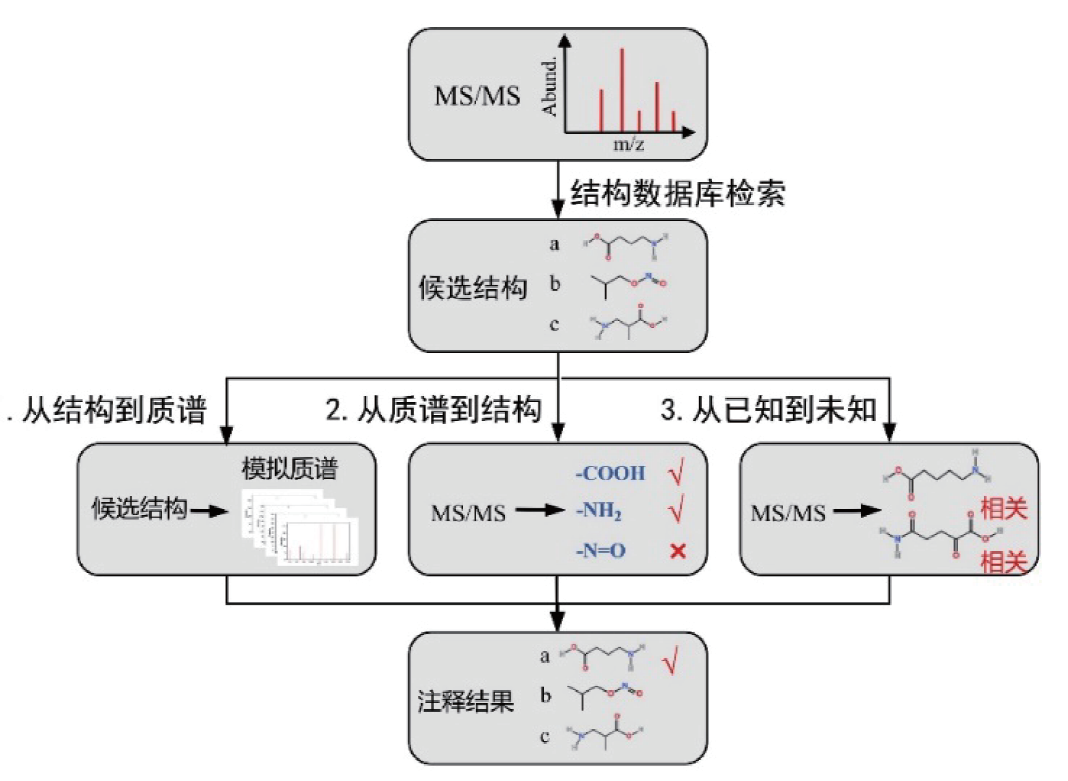
图1 基于MS/MS谱图搜索分子结构数据库的不同策略
Fig. 1 Strategies for searching molecular structure databases based on MS/MS
| 策略类型 Strategy type | 方法名称 Method name | 输入数据 Input data | 预测依据 Prediction basis | 是否有开源代码 Is there open source code available | 是否有可视化软件Is there any visualization software available | 官方网站 Official website |
|---|---|---|---|---|---|---|
| 从结构到谱图 | CFM-ID | 单张/多张谱图 | 模拟谱图 | 是 | 是 | https://cfmid.wishartlab.com/ |
| 3DmolMS | 单张/多张谱图 | 模拟谱图 | 是 | 否 | https://github.com/JosieHong/3DMolMS | |
| MassFormer | 单张/多张谱图 | 模拟谱图 | 是 | 否 | https://github.com/Roestlab/massformer | |
| MetFrag | 单张/多张谱图 | 碎片离子超集 | 是 | 是 | https://ipb-halle.github.io/MetFrag/ | |
| MS-Finder | 单张/多张谱图 | 碎片离子超集 | 是 | 是 | http://prime.psc.riken.jp/compms/msfinder/main.html | |
| MAGMa | 单张/多张谱图 | 碎片离子超集 | 是 | 是 | https://github.com/NLeSC/MAGMa | |
| 从谱图到结构 | SIRIUS | 单张/多张谱图 | 分子指纹 | 是 | 是 | https://bio.informatik.uni-jena.de/software/sirius |
| Mass2SMILES | 单张/多张谱图 | 分子结构 | 是 | 否 | https://github.com/volvox292/mass2smiles | |
| MS2Mol | 单张/多张谱图 | 分子结构 | 否 | 否 | 暂无 | |
| MSNovelist | 单张/多张谱图 | 分子结构 | 是 | 是 | https://github.com/meowcat/MSNovelist | |
| 从已知到未知 | MPEA | 非靶标组学数据 | 代谢反应 | 否 | 否 | 暂无 |
| MetDNA | 非靶标组学数据 | 代谢反应 | 是 | 是 | http://metdna.zhulab.cn/ | |
| iMet | 单张/多张谱图 | 代谢反应 | 是 | 是 | http://imet.seeslab.net/ | |
| SGMNS | 非靶标组学数据 | 代谢反应 | 否 | 否 | 暂无 | |
| DeepMASS | 单张/多张谱图 | 化学空间定位 | 是 | 是 | https://github.com/hcji/DeepMASS2_GUI |
表1 基于谱图搜索分子结构数据库的代表方法
Table 1 Representative methods for searching molecular structure databases based on MS/MS
| 策略类型 Strategy type | 方法名称 Method name | 输入数据 Input data | 预测依据 Prediction basis | 是否有开源代码 Is there open source code available | 是否有可视化软件Is there any visualization software available | 官方网站 Official website |
|---|---|---|---|---|---|---|
| 从结构到谱图 | CFM-ID | 单张/多张谱图 | 模拟谱图 | 是 | 是 | https://cfmid.wishartlab.com/ |
| 3DmolMS | 单张/多张谱图 | 模拟谱图 | 是 | 否 | https://github.com/JosieHong/3DMolMS | |
| MassFormer | 单张/多张谱图 | 模拟谱图 | 是 | 否 | https://github.com/Roestlab/massformer | |
| MetFrag | 单张/多张谱图 | 碎片离子超集 | 是 | 是 | https://ipb-halle.github.io/MetFrag/ | |
| MS-Finder | 单张/多张谱图 | 碎片离子超集 | 是 | 是 | http://prime.psc.riken.jp/compms/msfinder/main.html | |
| MAGMa | 单张/多张谱图 | 碎片离子超集 | 是 | 是 | https://github.com/NLeSC/MAGMa | |
| 从谱图到结构 | SIRIUS | 单张/多张谱图 | 分子指纹 | 是 | 是 | https://bio.informatik.uni-jena.de/software/sirius |
| Mass2SMILES | 单张/多张谱图 | 分子结构 | 是 | 否 | https://github.com/volvox292/mass2smiles | |
| MS2Mol | 单张/多张谱图 | 分子结构 | 否 | 否 | 暂无 | |
| MSNovelist | 单张/多张谱图 | 分子结构 | 是 | 是 | https://github.com/meowcat/MSNovelist | |
| 从已知到未知 | MPEA | 非靶标组学数据 | 代谢反应 | 否 | 否 | 暂无 |
| MetDNA | 非靶标组学数据 | 代谢反应 | 是 | 是 | http://metdna.zhulab.cn/ | |
| iMet | 单张/多张谱图 | 代谢反应 | 是 | 是 | http://imet.seeslab.net/ | |
| SGMNS | 非靶标组学数据 | 代谢反应 | 否 | 否 | 暂无 | |
| DeepMASS | 单张/多张谱图 | 化学空间定位 | 是 | 是 | https://github.com/hcji/DeepMASS2_GUI |
| [1] | Shen SQ, Zhan CS, Yang CK, et al. Metabolomics-centered mining of plant metabolic diversity and function: past decade and future perspectives[J]. Mol Plant, 2023, 16(1): 43-63. |
| [2] | Liu XY, Zhou LN, Shi XZ, et al. New advances in analytical methods for mass spectrometry-based large-scale metabolomics study[J]. Trac Trends Anal Chem, 2019, 121: 115665. |
| [3] |
Medema MH. The year 2020 in natural product bioinformatics: an overview of the latest tools and databases[J]. Nat Prod Rep, 2021, 38(2): 301-306.
doi: 10.1039/d0np00090f pmid: 33533785 |
| [4] | Bazsó FL, Ozohanics O, Schlosser G, et al. Quantitative comparison of tandem mass spectra obtained on various instruments[J]. J Am Soc Mass Spectrom, 2016, 27(8): 1357-1365. |
| [5] |
Hoang C, Uritboonthai W, Hoang L, et al. Tandem mass spectrometry across platforms[J]. Anal Chem, 2024, 96(14): 5478-5488.
doi: 10.1021/acs.analchem.3c05576 pmid: 38529642 |
| [6] | Wei JN, Belanger D, Adams RP, et al. Rapid prediction of electron-ionization mass spectrometry using neural networks[J]. ACS Cent Sci, 2019, 5(4): 700-708. |
| [7] |
Wang MX, Jarmusch AK, Vargas F, et al. Mass spectrometry searches using MASST[J]. Nat Biotechnol, 2020, 38(1): 23-26.
doi: 10.1038/s41587-019-0375-9 pmid: 31894142 |
| [8] |
Li YY, Kind T, Folz J, et al. Spectral entropy outperforms MS/MS dot product similarity for small-molecule compound identification[J]. Nat Methods, 2021, 18(12): 1524-1531.
doi: 10.1038/s41592-021-01331-z pmid: 34857935 |
| [9] | da Silva RR, Dorrestein PC, Quinn RA. Illuminating the dark matter in metabolomics[J]. Proc Natl Acad Sci U S A, 2015, 112(41): 12549-12550. |
| [10] |
Shen XT, Wang RH, Xiong X, et al. Metabolic reaction network-based recursive metabolite annotation for untargeted metabolomics[J]. Nat Commun, 2019, 10(1): 1516.
doi: 10.1038/s41467-019-09550-x pmid: 30944337 |
| [11] | Tian ZT, Hu X, Xu YY, et al. PMhub 1.0: a comprehensive plant metabolome database[J]. Nucleic Acids Res, 2024, 52(D1): D1579-D1587. |
| [12] |
Wang SC, Alseekh S, Fernie AR, et al. The structure and function of major plant metabolite modifications[J]. Mol Plant, 2019, 12(7): 899-919.
doi: S1674-2052(19)30201-1 pmid: 31200079 |
| [13] |
Böcker S. Searching molecular structure databases using tandem MS data: are we there yet?[J]. Curr Opin Chem Biol, 2017, 36:1-6.
doi: S1367-5931(16)30192-2 pmid: 28025165 |
| [14] |
Ásgeirsson V, Bauer CA, Grimme S. Quantum chemical calculation of electron ionization mass spectra for general organic and inorganic molecules[J]. Chem Sci, 2017, 8(7): 4879-4895.
doi: 10.1039/c7sc00601b pmid: 28959412 |
| [15] | Jumper J, Evans R, Pritzel A, et al. Highly accurate protein structure prediction with AlphaFold[J]. Nature, 2021, 596(7873): 583-589. |
| [16] | Cai YP, Zhou ZW, Zhu ZJ. Advanced analytical and informatic strategies for metabolite annotation in untargeted metabolomics[J]. Trac Trends Anal Chem, 2023, 158: 116903. |
| [17] |
Hu GL, Qiu MH. Machine learning-assisted structure annotation of natural products based on MS and NMR data[J]. Nat Prod Rep, 2023, 40(11): 1735-1753.
doi: 10.1039/d3np00025g pmid: 37519196 |
| [18] | Allen F, Greiner R, Wishart D. Competitive fragmentation modeling of ESI-MS/MS spectra for putative metabolite identification[J]. Metabolomics, 2015, 11(1): 98-110. |
| [19] | Allen F, Pon A, Wilson M, et al. CFM-ID: a web server for annotation, spectrum prediction and metabolite identification from tandem mass spectra[J]. Nucleic Acids Res, 2014, 42(W1): W94-W99. |
| [20] | Djoumbou-Feunang Y, Pon A, Karu N, et al. CFM-ID 3.0: significantly improved ESI-MS/MS prediction and compound identification[J]. Metabolites, 2019, 9(4): 72. |
| [21] |
Wang F, Liigand J, Tian SY, et al. CFM-ID 4.0: more accurate ESI-MS/MS spectral prediction and compound identification[J]. Anal Chem, 2021, 93(34): 11692-11700.
doi: 10.1021/acs.analchem.1c01465 pmid: 34403256 |
| [22] |
Wang F, Allen D, Tian SY, et al. CFM-ID 4.0-a web server for accurate MS-based metabolite identification[J]. Nucleic Acids Res, 2022, 50(W1): W165-W174.
doi: 10.1093/nar/gkac383 pmid: 35610037 |
| [23] | Hong YH, Li SJ, Welch CJ, et al. 3DMolMS: prediction of tandem mass spectra from 3D molecular conformations[J]. Bioinformatics, 2023, 39(6): btad354. |
| [24] | Young A, Röst H, Wang B. Tandem mass spectrum prediction for small molecules using graph transformers[J]. Nat Mach Intell, 2024, 6: 404-416. |
| [25] | Ruttkies C, Schymanski EL, Wolf S, et al. MetFrag relaunched: incorporating strategies beyond in silico fragmentation[J]. J Cheminform, 2016, 8: 3. |
| [26] |
Ruttkies C, Neumann S, Posch S. Improving MetFrag with statistical learning of fragment annotations[J]. BMC Bioinformatics, 2019, 20(1): 376.
doi: 10.1186/s12859-019-2954-7 pmid: 31277571 |
| [27] | Verdegem D, Lambrechts D, Carmeliet P, et al. Improved metabolite identification with MIDAS and MAGMa through MS/MS spectral dataset-driven parameter optimization[J]. Metabolomics, 2016, 12(6): 98. |
| [28] |
Tsugawa H, Kind T, Nakabayashi R, et al. Hydrogen rearrangement rules: computational MS/MS fragmentation and structure elucidation using MS-FINDER software[J]. Anal Chem, 2016, 88(16): 7946-7958.
doi: 10.1021/acs.analchem.6b00770 pmid: 27419259 |
| [29] |
Heinonen M, Shen HB, Zamboni N, et al. Metabolite identification and molecular fingerprint prediction through machine learning[J]. Bioinformatics, 2012, 28(18): 2333-2341.
doi: 10.1093/bioinformatics/bts437 pmid: 22815355 |
| [30] |
Rasche F, Svatos A, Maddula RK, et al. Computing fragmentation trees from tandem mass spectrometry data[J]. Anal Chem, 2011, 83(4): 1243-1251.
doi: 10.1021/ac101825k pmid: 21182243 |
| [31] | Shen HB, Dührkop K, Böcker S, et al. Metabolite identification through multiple kernel learning on fragmentation trees[J]. Bioinformatics, 2014, 30(12): i157-i164. |
| [32] | Dührkop K, Shen HB, Meusel M, et al. Searching molecular structure databases with tandem mass spectra using CSI: FingerID[J]. Proc Natl Acad Sci U S A, 2015, 112(41): 12580-12585. |
| [33] | Ludwig M, Dührkop K, Böcker S. Bayesian networks for mass spectrometric metabolite identification via molecular fingerprints[J]. Bioinformatics, 2018, 34(13): i333-i340. |
| [34] | Brouard C, Shen HB, Dührkop K, et al. Fast metabolite identification with Input Output Kernel Regression[J]. Bioinformatics, 2016, 32(12): i28-i36. |
| [35] |
Dührkop K, Fleischauer M, Ludwig M, et al. SIRIUS 4: a rapid tool for turning tandem mass spectra into metabolite structure information[J]. Nat Methods, 2019, 16(4): 299-302.
doi: 10.1038/s41592-019-0344-8 pmid: 30886413 |
| [36] |
Fan ZL, Alley A, Ghaffari K, et al. MetFID: artificial neural network-based compound fingerprint prediction for metabolite annotation[J]. Metabolomics, 2020, 16(10): 104.
doi: 10.1007/s11306-020-01726-7 pmid: 32997169 |
| [37] | Gao S, Chau HYK, Wang KJ, et al. Convolutional neural network-based compound fingerprint prediction for metabolite annotation[J]. Metabolites, 2022, 12(7): 605. |
| [38] | Dührkop K. Deep kernel learning improves molecular fingerprint prediction from tandem mass spectra[J]. Bioinformatics, 2022, 38(Suppl 1): i342-i349. |
| [39] | Goldman S, Wohlwend J, Stražar M, et al. Annotating metabolite mass spectra with domain-inspired chemical formula transformers[J]. Nat Mach Intell, 2023, 5: 965-979. |
| [40] | Mokaya M, Imrie F, van Hoorn WP, et al. Testing the limits of SMILES-based de novo molecular generation with curriculum and deep reinforcement learning[J]. Nat Mach Intell, 2023, 5: 386-394. |
| [41] | Qian H, Lin C, Zhao DW, et al. AlphaDrug: protein target specific de novo molecular generation[J]. PNAS Nexus, 2022, 1(4): pgac227. |
| [42] | Elser D, Huber F, Gaquerel E. Mass2SMILES: deep learning based fast prediction of structures and functional groups directly from high-resolution MS/MS spectra[J]. bioRxiv, 2023. DOI: 10.1101/2023.07.06.547963. |
| [43] | Butler T, Frandsen A, Lightheart R, et al. MS2Mol: a transformer model for illuminating dark chemical space from mass spectra[J]. ChemRxiv, 2023. https://chemrxiv.org/engage/chemrxiv/article-details/64f76a0279853bbd7829bf27. |
| [44] | Stravs MA, Dührkop K, Böcker S, et al. MSNovelist: de novo structure generation from mass spectra[J]. Nat Methods, 2022, 19(7): 865-870. |
| [45] |
Wang L, Ye H, Sun D, et al. Metabolic pathway extension approach for metabolomic biomarker identification[J]. Anal Chem, 2017, 89(2): 1229-1237.
doi: 10.1021/acs.analchem.6b03757 pmid: 27983783 |
| [46] |
Zhou ZW, Luo MD, Zhang HS, et al. Metabolite annotation from knowns to unknowns through knowledge-guided multi-layer metabolic networking[J]. Nat Commun, 2022, 13(1): 6656.
doi: 10.1038/s41467-022-34537-6 pmid: 36333358 |
| [47] | Wang XX, Li C, Li ZF, et al. A structure-guided molecular network strategy for global untargeted metabolomics data annotation[J]. Anal Chem, 2023, 95(31): 11603-11612. |
| [48] |
Aguilar-Mogas A, Sales-Pardo M, Navarro M, et al. iMet: a network-based computational tool to assist in the annotation of metabolites from tandem mass spectra[J]. Anal Chem, 2017, 89(6): 3474-3482.
doi: 10.1021/acs.analchem.6b04512 pmid: 28221024 |
| [49] |
Ji HC, Xu YM, Lu HM, et al. Deep MS/MS-aided structural-similarity scoring for unknown metabolite identification[J]. Anal Chem, 2019, 91(9): 5629-5637.
doi: 10.1021/acs.analchem.8b05405 pmid: 30990670 |
| [50] | Huber F, Ridder L, Verhoeven S, et al. Spec2Vec: improved mass spectral similarity scoring through learning of structural relationships[J]. PLoS Comput Biol, 2021, 17(2): e1008724. |
| [51] | Huber F, van der Burg S, van der Hooft JJJ, et al. MS2DeepScore: a novel deep learning similarity measure to compare tandem mass spectra[J]. J Cheminform, 2021, 13(1): 84. |
| [52] |
Guo H, Xue KB, Sun HM, et al. Contrastive learning-based embedder for the representation of tandem mass spectra[J]. Anal Chem, 2023, 95(20): 7888-7896.
doi: 10.1021/acs.analchem.3c00260 pmid: 37172113 |
| [53] | Blaženović I, Kind T, Torbašinović H, et al. Comprehensive comparison of in silico MS/MS fragmentation tools of the CASMI contest: database boosting is needed to achieve 93% accuracy[J]. J Cheminform, 2017, 9(1): 32. |
| [54] | Hoffmann MA, Kretschmer F, Ludwig M, et al. MAD HATTER correctly annotates 98% of small molecule tandem mass spectra searching in PubChem[J]. Metabolites, 2023, 13(3): 314. |
| [55] |
Domingo-Almenara X, Guijas C, Billings E, et al. The METLIN small molecule dataset for machine learning-based retention time prediction[J]. Nat Commun, 2019, 10(1): 5811.
doi: 10.1038/s41467-019-13680-7 pmid: 31862874 |
| [56] |
Kretschmer F, Harrieder EM, Hoffmann MA, et al. RepoRT: a comprehensive repository for small molecule retention times[J]. Nat Methods, 2024, 21(2): 153-155.
doi: 10.1038/s41592-023-02143-z pmid: 38191934 |
| [57] |
Zhang HS, Luo MD, Wang HM, et al. AllCCS2: curation of ion mobility collision cross-section atlas for small molecules using comprehensive molecular representations[J]. Anal Chem, 2023, 95(37): 13913-13921.
doi: 10.1021/acs.analchem.3c02267 pmid: 37664900 |
| [1] | 宋兵芳, 柳宁, 程新艳, 徐晓斌, 田文茂, 高悦, 毕阳, 王毅. 马铃薯G6PDH基因家族鉴定及其在损伤块茎的表达分析[J]. 生物技术通报, 2024, 40(9): 104-112. |
| [2] | 谭博文, 张懿, 张鹏, 王振宇, 马秋香. 木薯镁离子转运蛋白家族基因的鉴定及生物信息学分析[J]. 生物技术通报, 2024, 40(9): 20-32. |
| [3] | 满全财, 孟姿诺, 李伟, 蔡心汝, 苏润东, 付长青, 高顺娟, 崔江慧. 马铃薯AQP基因家族鉴定及表达分析[J]. 生物技术通报, 2024, 40(9): 51-63. |
| [4] | 吴娟, 武小娟, 王沛捷, 谢锐, 聂虎帅, 李楠, 马艳红. 彩色马铃薯花青素合成相关ERF基因筛选及表达分析[J]. 生物技术通报, 2024, 40(9): 82-91. |
| [5] | 武帅, 辛燕妮, 买春海, 穆晓娅, 王敏, 岳爱琴, 赵晋忠, 吴慎杰, 杜维俊, 王利祥. 大豆GS基因家族全基因组鉴定及胁迫响应分析[J]. 生物技术通报, 2024, 40(8): 63-73. |
| [6] | 杨巍, 赵丽芬, 唐兵, 周麟笔, 杨娟, 莫传园, 张宝会, 李飞, 阮松林, 邓英. 芥菜SRO基因家族全基因组鉴定与表达分析[J]. 生物技术通报, 2024, 40(8): 129-141. |
| [7] | 周麟, 黄顺满, 苏文坤, 姚响, 屈燕. 滇山茶bHLH基因家族鉴定及花色形成相关基因筛选[J]. 生物技术通报, 2024, 40(8): 142-151. |
| [8] | 张明亚, 庞胜群, 刘玉东, 苏永峰, 牛博文, 韩琼琼. 番茄FAD基因家族的鉴定与表达分析[J]. 生物技术通报, 2024, 40(7): 150-162. |
| [9] | 臧文蕊, 马明, 砗根, 哈斯阿古拉. 甜瓜BZR转录因子家族基因的全基因组鉴定及表达模式分析[J]. 生物技术通报, 2024, 40(7): 163-171. |
| [10] | 王健, 杨莎, 孙庆文, 陈宏宇, 杨涛, 黄园. 金钗石斛bHLH转录因子家族全基因组鉴定及表达分析[J]. 生物技术通报, 2024, 40(6): 203-218. |
| [11] | 李梦然, 叶伟, 李赛妮, 张维阳, 李建军, 章卫民. Lithocarols类化合物生物合成基因litI的表达及其启动子功能分析[J]. 生物技术通报, 2024, 40(6): 310-318. |
| [12] | 苑海鹏, 叶云舒, 司皓, 纪秋研, 张玉红. 丛枝菌根真菌对植物逆境胁迫抗性及次生代谢产物合成的影响[J]. 生物技术通报, 2024, 40(6): 45-56. |
| [13] | 胡永波, 雷雨田, 杨永森, 陈馨, 林黄昉, 林碧英, 刘爽, 毕格, 申宝营. 黄瓜和南瓜Bcl-2相关抗凋亡家族全基因组鉴定与表达模式分析[J]. 生物技术通报, 2024, 40(6): 219-237. |
| [14] | 常雪瑞, 王田田, 王静. 辣椒E2基因家族的鉴定及分析[J]. 生物技术通报, 2024, 40(6): 238-250. |
| [15] | 刘蓉, 田闵玉, 李光泽, 谭成方, 阮颖, 刘春林. 甘蓝型油菜REVEILLE家族鉴定及诱导表达分析[J]. 生物技术通报, 2024, 40(6): 161-171. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||